Towards A New Approach to Real-Time AI Insights Without Moving Any Data
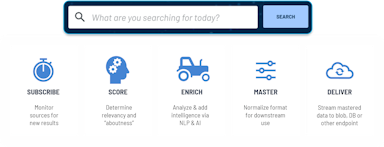
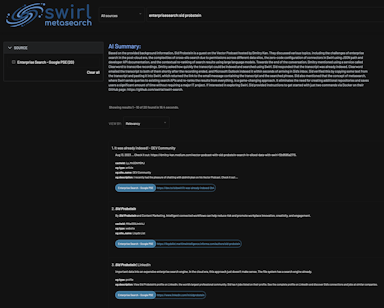
SWIRL is moving towards bringing AI to the data instead of data to the AI. Breaking conventional barriers and utilizing Reader LLMs and eliminating the need for extensive data movement, SWIRL enables enterprises to generate valuable AI insights without complex IT projects.